
티스토리 뷰
Python과 Graphviz를 활용한 Decision-Tree 라이브러리 제작
0. 여는말¶
"마음대로 Visual Customizing이 가능한 Machine Learning Library를
내가 직접 만들어볼 수 있을까?"
↓
"나도 만들 수 있다!"

1. Decision-Tree에 대한 이해¶
Decision-Tree(이하 의사결정나무)란 어떤 항목에 대한 관측값들을(Variables) 목표값(Target)에 연결시켜주는 분석 기법으로, 관측값과 목표값을 연결할 때 의사결정 규칙과 그 결과들을 Tree 구조로 만든 분류 모델이다. 이름에서도 쉽게 알 수 있듯이 나무가 넓은 몸통에서 시작해서 위쪽으로 따라가면서 점점 더 좁은 가지로 갈라지는 방식을 반영하는 구조이며, 각 특징과 잠재적 결과 간의 관계를 모델링하기 위해 결정을 분기시키는 구조를 사용한다. 또한, 의사결정나무는 가장 널리 사용되는 하나의 머신러닝기법이며, 거의 모든 종류의 데이터를 모델링하는데 적용 가능하다. 더불어 시각적이고 명시적인 방법으로 의사 결정 과정과 결정된 의사를 보여주는데 사용된다.

<의사결정나무 모델을 쉽게 보여주는 그림 - 자체 제작>
크게 출력변수가 연속형인 회귀나무(regression tree)와 범주형인 분류나무(classification tree)로 나눌 수 있으며, 우선 의사결정나무를 이해하고 구현하는데 있어 가장 중요한 두 가지 쟁점에 대하여 짚고 넘어가고자 한다.
의사결정나무가 직면하게 될 첫번째 문제는 분할 조건이 되는 특징을 식별하는 것이다. 나무를 구성하는 알고리즘에는 주로 하향식 기법이 사용되며, 각 진행 단계에서는 주어진 데이터 집합을 가장 적합한 기준으로 분할하는 변수값이 선택된다. 일반적으로 지니계수를 이용한 불순도 측정, 엔트로피를 이용한 정보획득량 확인, 평균제곱오차를 이용한 회귀트리 분할이 있으며, 서로 다른 알고리즘들은 ”분할의 적합성"을 측정하는 각자의 기준이 있다. 이러한 기준들은 보통 부분 집합 안에서의 목표 변수의 동질성을 측정하며, 데이터 집합의 분할이 얼마나 ”적합한지" 측정하는데 사용된다.
① 지니계수를 이용한 불순도 측정¶
집합에 이질적인 것이 얼마나 섞였는지를 측정하는 지표, 어떤 집합에서 한 항목을 뽑아 무작위로 라벨을 추정할 때 틀릴 확률, 집합에 있는 항목이 모두 같다면 지니 불순도는 최소값(0)을 갖게 되며이 집합은 완전히 순수하다고 할 수 있다. 항목의 집합에 대한 지니 불순도를 계산하기 위하여, $i \in \{1, 2, ..., m\}$ 인 ${\displaystyle i} i$를 가정해보자, 그리고 ${\displaystyle f_{i}}$를 ${\displaystyle i}$로 표시된 집합 안의 항목의 부분이라고 했을 때,

로 나타낼 수 있다.
② 엔트로피를 이용한 정보획득량 확인¶
정보 이론의 엔트로피의 개념에 근거를 둔 불순도 측정 방법으로, 엔트로피란 클래스 값의 집합에서 무작위성(randomness) 또는 무질서(disorder)를 정량화한다. 엔트로피가 높은 집합은 매우 다양하며, 같은 집합에 속해있는 다른 아이템에 대해 뚜렷한 공통점이 없기 때문에 정보를 거의 제공하지 않는다. 즉, 엔트로피가 낮으면 얻을 수 있는 정보의 양(정보획득량)이 많다.
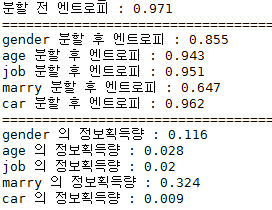
정보획득량은 _(나무 분할 전 클래스 변수의 엔트로피) - (분할 후 각 변수의 엔트로피)_로 나타낼 수 있으며, 의사결정나무는 엔트로피를 줄이는 분할(정보획득량이 가장 많은 변수)을 찾고 궁극적으로 그룹 내 동질성을 증가시키려고 한다. 엔트로피를 구하는 공식은 아래와 같다.
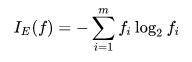

③ 평균제곱오차를 이용한 회귀트리 분할¶
목표 변수가 연속적일 경우 자주 사용되며, 평균제곱오차를 활용하는 방법이다. 평균제곱오차는 오차의 제곱에 평균을 취한 것으로, 작을수록 원본과의 오차가 작아 추측한 값의 정확성이 높다. 아래 식에서 ${\displaystyle {\hat {Y}}}$는 실제 벡터값이며, ${\displaystyle Y}$는 관측값(평균)의 벡터값을 뜻한다.
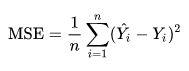

본 작에서는 2번의 엔트로피를 이용한 정보획득량으로 의사결정나무 구현 시 분할 조건이 되는 특징을 식별하였다.
2) 그래프 탐색¶
의사결정나무를 구현하는데 있어 두번째로 부딪히는 쟁점은 그래프를 탐색하는 것이다. 의사결정나무의 큰 장점 중 하나는 통계적 지식이 없는 누가 보아도 모델이 생성된 구조를 사람이 읽을 수 있는 형식으로 출력하는 것이며, 이는 소프트웨어의 테스트 방법인 White box에 속한다. 그래프 탐색 알고리즘은 의사결정나무와 같은 구조의 데이터를 탐색하는 기능이지만, 어떠한 방법으로 의사결정나무를 시각화할 지 선택하는 과정에도 큰 영향을 미친다.
그래프 탐색 방법에는 크게 깊이우선탐색(Depth First Search, 이하 DFS)과 너비우선탐색(Breadth First Search, 이하 BFS) 두 가지 방법이 있다.
① 깊이우선탐색(Depth First Search, 이하 DFS)¶
DFS를 쉽게 설명한다면 끝이 보일때까지 탐색하는 알고리즘이다. 우선 시작점과 인접한 선들을 검사하다가, 아직 가지 않은 선이 있다면 그 간선을 따라 계속 탐색을 진행한다. 이 과정에서 더 이상 갈 곳이 없다면 마지막에 왔던 선을 기준으로 아직 탐색하지 않은 이동가능한 방향으로 다시 탐색을 진행한다.

② 너비우선탐색(Breadth First Search, 이하 BFS)¶
BFS는 위의 DFS와 다르게 현재 위치에서 동일한 깊이(depth)의 노드를 확인한다. 이후 더 이상 갈 곳이 없다면 다음 깊이(depth)로 이동하여 이웃 노드들의 또 다른 이웃 노드들을 방문하며 탐색을 진행한다.

2. Decision-Tree의 장/단점¶
의사결정나무는 아래와 같은 장/단점을 가지고 있으며, 무엇보다 누구나 쉽게 결과를 확인하고 응용할 수 있다는 큰 장점으로 인해 현재 여러 사업 분야 데이터 분석의 유용한 도구로 사용되고 있다. 또한, 법적인 이유로 분류 방법이 투명해야 하거나 다른 사람과 결과를 공유해야 하는 업무에도 주로 활용되며, 데이터의 기본적인 분산 및 형태를 확인하기 위한 방법이기도 하다.
하지만, 데이터의 특징에 따라 트리의 크기가 매우 커지고 복잡해진다면 모델이 데이터에 과적합되는 경향을 가지며 예측력이 저하되고 해석 또한 어렵다. 더불어 출력변수가 연속형인 회귀모형에서는 그 예측력이 떨어지며, 특히 자료에 약간의 변화가 있는 경우에 전혀 다른 결과를 줄 수도 있는 (즉, 분산이 매우 큰) 방법이기도 하다. 이러한 단점은 배깅(bagging), 부스팅(Boosting), Random Forest와 같은 앙상블(ensemble) 알고리즘을 적용하여 의사결정나무의 분산을 줄이는 것으로 보완한다.
나무를 축소하는 '가지치기'작업이 필요하다. |
|
변수들간의 상관관계에 따른 분류가 불가능하다. |
|
이상치에도 강한 안정적인 모델을 생성한다. |
3. 기존 Decision-Tree Package/Module¶
1) rpart(R)¶
R에서 사용가능한 Package인 Rpart는 의사결정나무 모델을 생성하기 위한 매우 쉽고 간편한 함수들을 제공한다.
R 혹은 R Studio를 실행한 후,
install.package("rpart")
library(rpart)
로 rpart 패키지를 불러온다.
만드는 함수 |
control=rpart.control(minsplit=**최소 depth**)) |
또한, 확장성이 좋은 R의 장점으로 인해 rattle 패키지와 함께 사용하면 시각적으로 의사결정나무를 쉽게 구현할 수 있다.
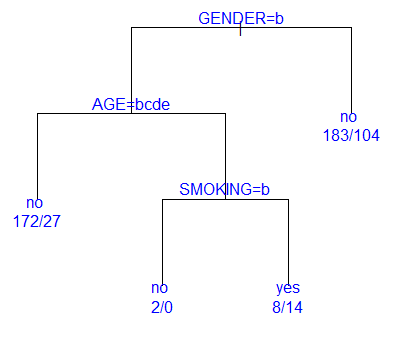 |
|
  |
|
  |

2) sklearn(Python)¶
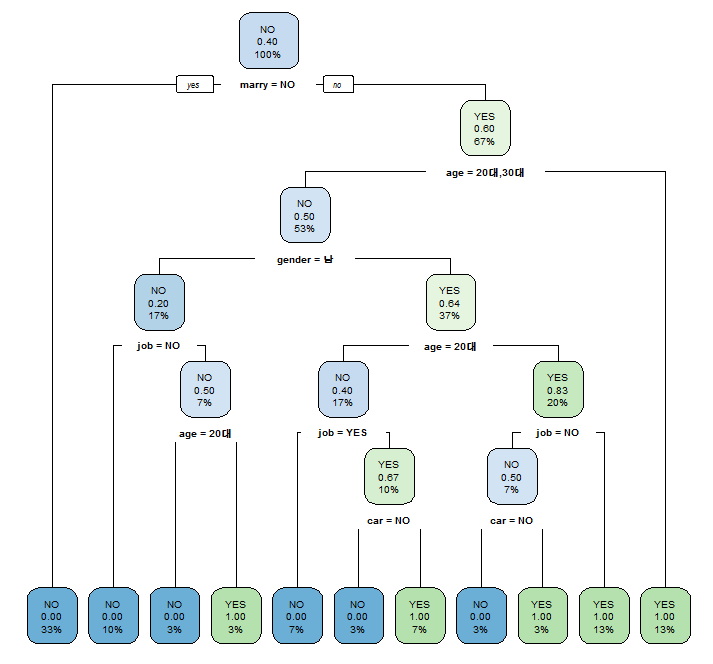
sklearn, 정확히 scikit-learn은 2007년 Google 썸머 코드에서 처음 구현되었으며 현재 파이썬으로 구현된 가장 유명한 기계학습(machine learning) 오픈 소스 라이브러리다. 의사결정나무 이외에도 서포트 벡터 머신(SVM), 나이브 베이즈(Naive Bayes) 등의 지도/비지도 학습의 알고리즘을 쉽게 구현할 수 있다. Python의 호환성으로 인해 graphviz와 같은 그래프 시각화 소프트웨어와 연동이 가능하여 시각화가 가능하고, 이로 인해 쉽게 다양한 방법으로 시각화가 가능하다는 장점이 있다.

sklearn을 활용한 Iris 데이터 의사결정나무 시각화[3]
4. Decision-Tree 구현 목표 및 상세내용¶
1) 구현목표¶
의사결정나무를 구현하는 기존의 패키지와 라이브러리를 사용하면서 아래와 같은 아쉬운 점이 있었다.
- 분할 이후 각 node 별 데이터 확인이 불가
→ 기존 의사결정나무 구현 시 의아한 최종 결과가 나왔을 때, 각 node에 해당하는(속하는) 데이터를 확인할 수 없었다.
이를 확인하는 작업에 적지 않은 시간이 소요되었으며, 의사결정나무를 만들었을 때 분할된 데이터를 즉각적으로
확인할 수 있다면 나무 모델을 이해하고 해석하는 것뿐 아니라 응용하는데 있어 도움이 될 것이라 판단하였다.
- Visualization Customizing의 어려움
→ sklearn(Python)은 다른 graph visualization software와 연동이 가능하지만 이를 조작하기 위해 노력해야하는 수고가
많았으며, rpart(R)은 기존 시각화 세팅이 나쁘지는 않았으나, Customizing 기능은 제공하지 않았다.
아쉬운 점을 느낀 것에서 끝나지않고, 나아가 이를 가능케하는 의사결정나무 구현에 도전하였다.
2) 상세내용¶
① flowchart¶
언어로는 Python을 선택하였으며 코드의 전반적인 흐름은
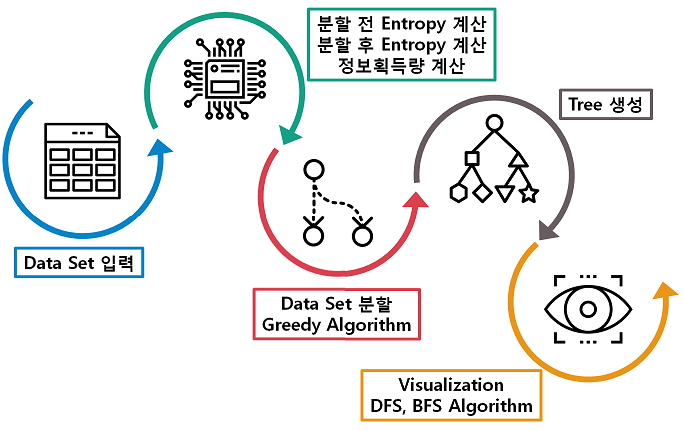
Data Set 입력 → 정보획득량 계산을 위한 엔트로피 계산 → Data Set 분할 → Tree 구조 생성 → Visualization의 순서로 구성되었다.

② Library¶
③ function¶
해당 컬럼값의 종류를 리턴 |
|
엔트로피(분할 전 엔트로피)를 산정 |
|
엔트로피(분할 후 엔트로피)를 측정 |
|
엔트로피가 가장 작은 컬럼을 리턴 |
|
④ Result¶
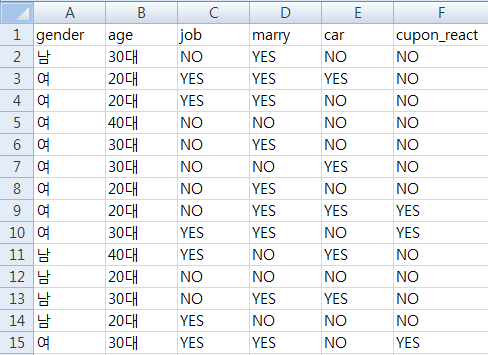
- Input값의 Data Set을 정보획득량에 따라 나무 구조로 재구성하였고, 이때 각 node별 데이터를 확인할 수 있게 하였다.
 |
  |
  |

- Graphviz를 사용해 의사결정나무 시각화를 구현하였으며, Custominzing 역시 가능하도록 하였다.
| 시각화 1 |  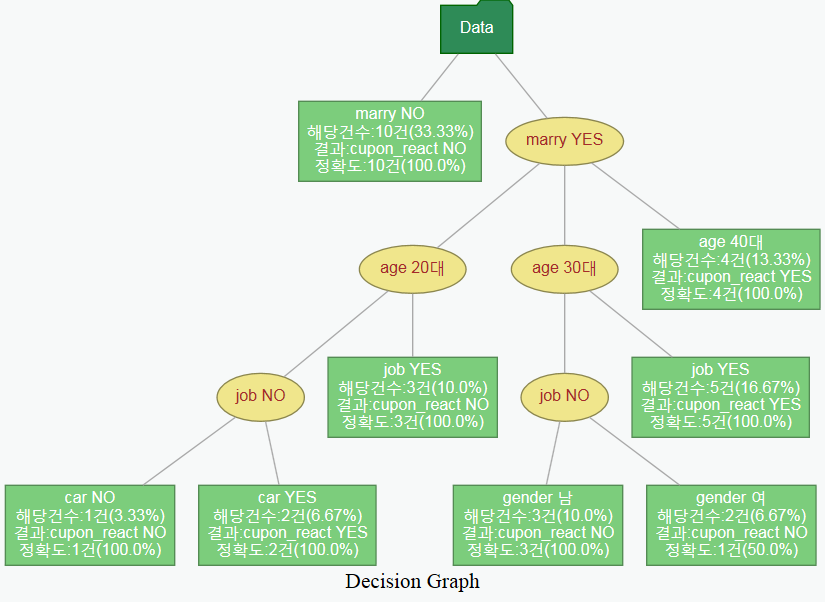 |
|---|---|
| 시각화 2 |   |
| 시각화 3 |  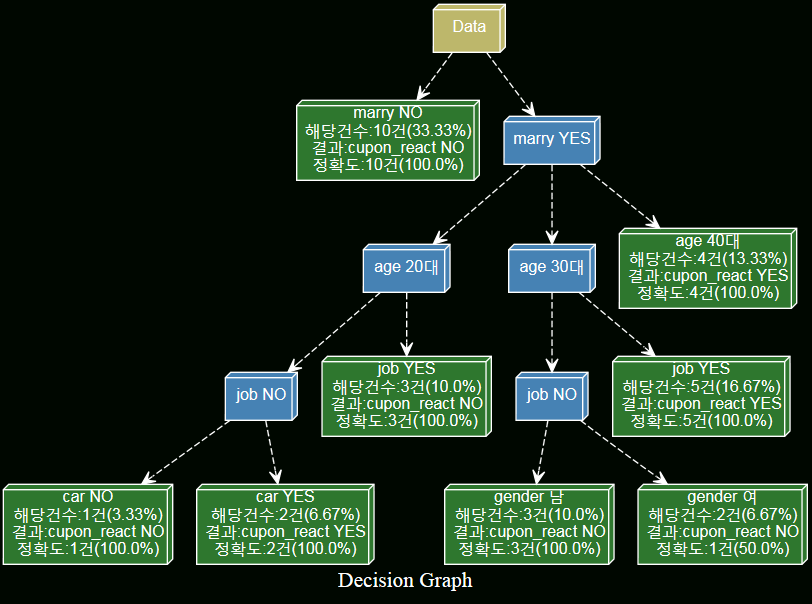 |
5. 닫는말¶
본 프로젝트를 통해 의사결정나무의 데이터 분할부터 시각화까지 전 과정을 구현하며 작동원리와 관련 이론, 코드 구현에 사용한 pandas, graphviz의 사용법에 대하여 숙지하게 되었다. 또한, 의사결정나무 알고리즘을 어떤 실무 상황에서 어떻게 활용해야 더욱 효과적일지 깊게 생각해볼 수 있었다.
컬럼과 Label이 연속형일때 사용하는 회귀트리도 구현하고자 했으나, 구현한 분류트리와 분할 규칙이 다르고 규칙을 명확하게 확인하기 어려워 진행하지 못했다. 추후 이를 보완하고, 기회가 된다면 CART(Classification And Regression Tree) 알고리즘과 같이 스스로 연속형 변수와 범주형 변수를 구분하는 방법을 적용한 라이브러리로 발전시키도록 하겠다.
참조 1 Wikipedia
참조 2 개인블로그
참조 3 개인블로그
참조 4 도서출판 더알음
참조 5 UCI ML Repository
'Python' 카테고리의 다른 글
| [Python] Python을 통한 Machine Learning 구현 - (1)KNN (2) | 2018.02.07 |
|---|
- Total
- Today
- Yesterday
- 하둡설치가이드
- 하둡설치
- hadoop setup
- data
- hadoop 2.7 install
- 하둡
- Big Data
- hadoop2.7
- hadoop install
- 빅데이터
- 데이터 분석
- hadoop
- Data Analysis
- 하둡2.7
- 하둡 설치 가이드
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |